And if you want to have step-by-step instructions on how to create it in SPSS, see this SAGE resource


PSPP is a program for statistical analysis of sampled data. It is particularly suited to the analysis and manipulation of very large data sets. In addition to statistical hypothesis tests such as t-tests, analysis of variance and non-parametric tests, PSPP can also perform linear regression and is a very powerful tool for recoding and sorting of data and for calculating metrics such as skewness and kurtosis.PSPP is designed as a Free replacement for SPSS. That is to say, it behaves as experienced SPSS users would expect, and their system files and syntax files can be used in PSPP with little or no modification, and will produce similar results.
PSPP supports numeric variables and string variables up to 32767 bytes long. Variable names may be up to 255 bytes in length. There are no artificial limits on the number of variables or cases. In a few instances, the default behaviour of PSPP differs where the developers believe enhancements are desirable or it makes sense to do so, but this can be overridden by the user if desired.
Cohen’s d = Mean difference
Standard deviation




Probability sampling approaches allow you to generalize to the full population, since it ensures that special random characteristics are likely to be distributed evenly across the units included and excluded in / from the sample. It therefore is likely to yield a less biased sample and the results could be said to apply to the full population (if the appropriate sample size was selected). Different kinds of probability sampling approaches are possible.
The figures below demonstrate the different approaches. Assume each number is a unique member of the population, assume that each group consists of discreet mutually exclusive members of the population (In columns) and assume that each cluster (delineated by a block) is a group of members in the same geographic area.

With simple random sampling the sample is selected from the whole population using a table of numbers. Note that this does not necessarily ensure balanced representation amongst different groups.
With stratified random sampling, a set number of participants from each group can be selected. Note that this does not necessarily ensure that the most economical approach is used. In the example some cases from almost all of the geographic clusters are included.
With cluster sampling, a set number of clusters are randomly selected (in this case 4) with a set number of randomly selected units within each cluster (in this case 5). Although this will be more economical in terms of fieldwork costs because travel to different clusters have been limited, it does not necessarily guarantee equal representation of groups.
With systematic sampling, a set pattern is systematically applied to select participants. In the case of the example above, every 11th member of the population were selected. Note that it did not require a random table of numbers, but were still subject to the same limitations as the simple random sample.
| Type of Probability Samples | When is it applicable | Drawbacks |
| Simple Random Sampling (I.e.randomly select 50 schools off a list with all schools in the country) | It is ideal for statistical purposes | · It may be difficult to achieve in practice · It requires a precise list of the whole population · It is costly to conduct as those sampled may be spread over a wide area. |
| Stratified Random Sampling (I.e. Randomly select 50 schools per strata such as province) | · It ensures better coverage of the population than simple random sampling. · It is administratively more convenient to stratify a sample – interviewers can be specifically trained to manage particular strata (e.g. age, gender, ethnic or language groups). | · Difficulty in identifying appropriate strata. · More complex to organize and analyse results |
| Cluster Sampling (I.e. split the schools in a province up in geographical clusters, select 10 clusters randomly, and then proceed to visit 20 schools within each cluster) | More cost effective in terms of travel, thereby producing a reduction in the overall cost | · Units in a cluster may be very similar and therefore are less likely to represent the whole population · Cluster sampling has a larger sampling error than simple random sampling. |
| Systematic Sampling (i.e. a set pattern is applied to the data set, e.g. every 11th member is selected) | It spreads the sample more uniformly over the population and is easier to conduct than simple random sampling. | The system may interact with a concealed pattern in the population. |
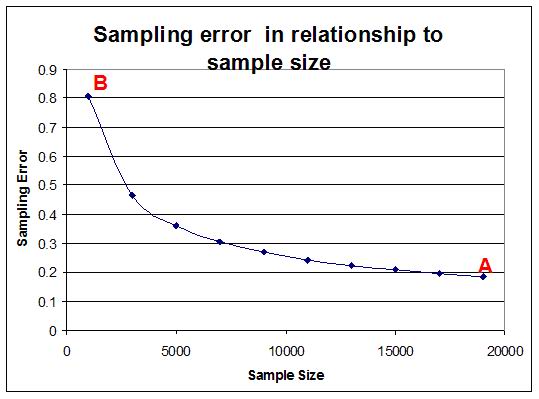
In the General Household Survey, the sample included 18,657 children of school going age for the whole of South Africa. This sample was intended to represent approximately 8,242,044 children of school going age in the total South African population. Because it is a sample there will be some degree of error in the results. However the sampling error in this case approaches a very respectable 0.2% (See point A in the graph above) because of the large sample size.
What does this mean? Well, if we are reporting values for a parameter - e.g. the number of children that are in school - and find that the result for the sample is 97.5%, it means that the same parameter in the population – the number of children that are in school - will range between 97.3% (97.5%-0.2%) and 97.7% (97.5%+0.2%). Note that if the sample included only 1000 people that the sampling error would have increased to 0.8%.
Statistical significance
It is not always correct to manually compare averages and percentages when one is interested in differences between different years’ or different provinces’ results. Percentages and averages are single figures that do not always adequately describe the variance on a specific variable. One needs to be convinced that a “statistically significant” difference is observed between two values before one can say one value is “better” or “poorer” than the other.
In order to make confident statements of comparison about averages, one would need to conduct tests of statistical significance (e.g. a t-test) using an applicable software package. These tests take into account the variance attributable to the sampling error and the normal variance around a mean. A person with some skills in statistical analysis could produce results (In a statistical analysis package or even in a spreadsheet application such as excel) that will allow adequate comparison of means between and within groups.
Weighting
Earlier we mentioned that one of the properties that influence representivity of sample results is whether the people all have the same probability of selection. If one had a complete list of all people in South Africa and a specific address for each one of them, you could have randomly selected people from this list and visited each one of them at their address. In this scenario each person has an equal chance to be included in the sample because you have the relevant details about them.
Unfortunately, researchers rarely have this kind of list and the costs would be very high if you had to visit each of the people you selected at their own address – You would probably end up speaking to one person per address only. To save time and money researchers rather speak to all people in a specific household that they select, but then all of the individuals in the population no longer have the same likelihood to be selected because this is impacted by which households are selected.
The probability of selection is even further complicated if one considers that researcher also don’t have a list with all households in South Africa to randomly select from. To get around this problem they use information about neighbourhoods and geographic locations to identify areas in which they will select households. When a survey uses neighbourhoods or households as a sampling unit, there is little control over the number of persons that will be included in the survey. One household in area A could have 5 people in it and the household next door might have 3 people in it. In order to ensure that the individuals within households (and households within neighbourhoods or household sampling units) are not disproportionately represented in relationship to known population parameters, weighting is applied.
Different weighting procedures can be used to correct for the probability of selection. The weighting procedure is usually selected by statisticians involved with the sampling in the survey. The weight to apply to each individual is usually captured as a variable somewhere in the dataset. Although it is beyond the scope of this manual to explain different ways of weighting it is important to consider that weighting will affect the percentages and absolute numbers produced.
The following table indicates how the percentage of 7 – 14 year olds that indicate they attend school in the General Household Survey differ when weighting is applied and when it is not applied.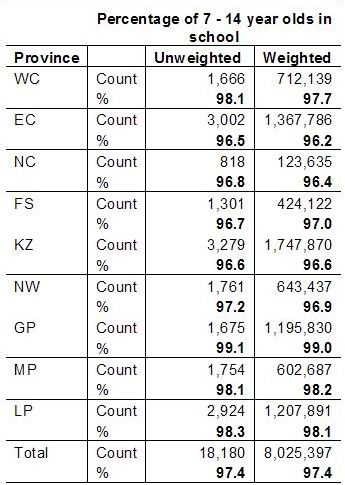
When analysing the data, it is important to ensure that the weighting is taken into account – both when percentages, averages and absolute numbers are computed. It is necessary to use a statistical analysis programme such as SPSS™ or STATA™ to produce any results.
------------------------------------
Attachment two: Household Survey Sampling Approaches
(This was produced by Khulisa Management Services)
For each of the three cities, Khulisa first conducted a purposive geographic sample, to be in alignment with the racial population and Living Standard Measure (LSM) levels three to seven[1] of the geographic area. LSM is used as an indicator of the principle index of the South African consumer market. It was first developed in 1991 by the South African Advertising Research Foundation (SAARF).
For each racial cell in the sampling framework above, the following methodology was used. Four by four, uniform grids were placed over the selected geographic areas. Cells from these grids were randomly selected and a subsequent ten by ten grid placed over the selected cell. A cell from the ten by ten grid was randomly selected after which a street block was selected. A street intersection was noted, and a house was randomly selected (left-side and out of ten houses on the block). The street intersection was the starting point as you move down the street/block. The primary sampling site was located on the left side of the street, with the alternative site being located on the right side of the street. The location of the two primary houses and two replacement houses was given to each fieldworker. This equated to 1200 sample sites and 1200 replacement sites picked from 600 street blocks. This strategy ensured that two fieldworkers – male and female – can work in the same street thus improving the safety levels of the fieldworkers, especially the females.
In an area with apartment buildings (like Joubert Park), after picking the apartment building the fieldworkers were instructed to select the second floor and the number indicated on the instructions for the flat to carry out the interviews.
If there was no house or flat in the pre-selected location, then it was recorded as an Unfeasible Site on the Fieldworkers’ Instrument Control Sheet. Similarly, if there were no eligible respondents in the household, then that was recorded as ALL Ineligible Respondents on the control sheet.
[1] The SABC ConsumerScope (2003) characterizes LSM levels three through seven by the following average monthly household income levels: Level 3: R1104; Level 4: R1534; Level 5: R2195; Level 6: R3575 and Level 7: R5504.